Проект МТС-фитнес
МТС-фитнес – приложение, которое сможет определять правильность выполнения упражнения, подсчитывать количество выполненных подходов и давать рекомендации по тренировке аудио-визуальным способом.
Основа приложения в распознавании скелетной модели тренирующегося, распознавания движений, определения законченности действия и его правильности.
Первоначально разрабатывался для серверной обработки видео.
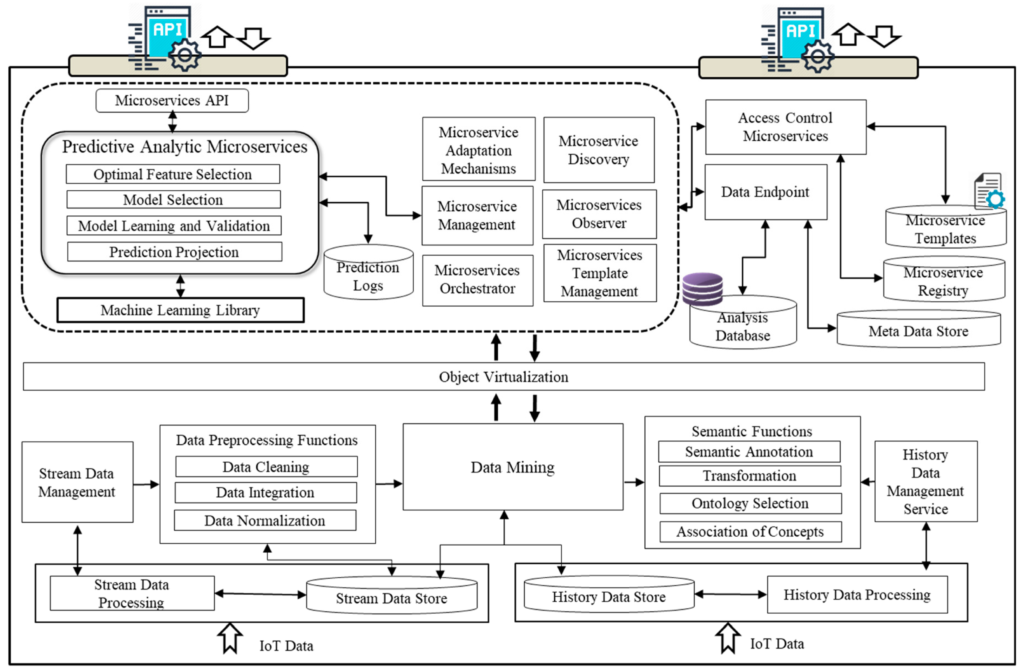
Схема работы данного сервиса представляла собой стандартное приложение с микросервисной архитектурой, которая позволила горизонтально масштабировать его.
Основные плюсы такого подхода:
- контроль над данными, все данные доступны из одного места, разработка упрощается
- возможность регулярно дообучать систему по произвольному выбранному набору данных
- хранение всего кода на сервере, большая безопасность интеллектуальной собственности
- единая версия детектора у всех клиентов
- возможность синхронизации между устройствами клиента
Основной недостаток данной схемы – отсутствие мгновенной обратной связи у клиента. Ждать результата приходилось до трех минут, в случае отправки большого видео в час пик.
Как дополнительные минусы:
- невозможность работы без сети интернет
- большая нагрузка на сервер
- потребление трафика клиентом
Как решение проблемы – перенос части расчетов на мобильные устройства, такие как SBC и смартфоны.
Архитектура разделения клиентской части ML и серверной.
Приложение Фитнес состоит их нескольких модулей, перенос всех не стоял задачей, так как в таком случае мы бы больше потеряли, чем приобрели.
Это тема для отдельного обсуждения, так как есть стартапы, развивающие похожие приложения, которые пошли по пути полного переноса кода на клиентское устройство. Как мы увидим дальше, это возможно при текущих фреймворках. Но в таком случае они теряют контроль над данными и дальнейшим развитием именно обработки данных пользователей. Из главных плюсов полного переноса кода – снижение затрат на поддержку и развитие серверной части.
В нашем случае архитектура получилась следующей:
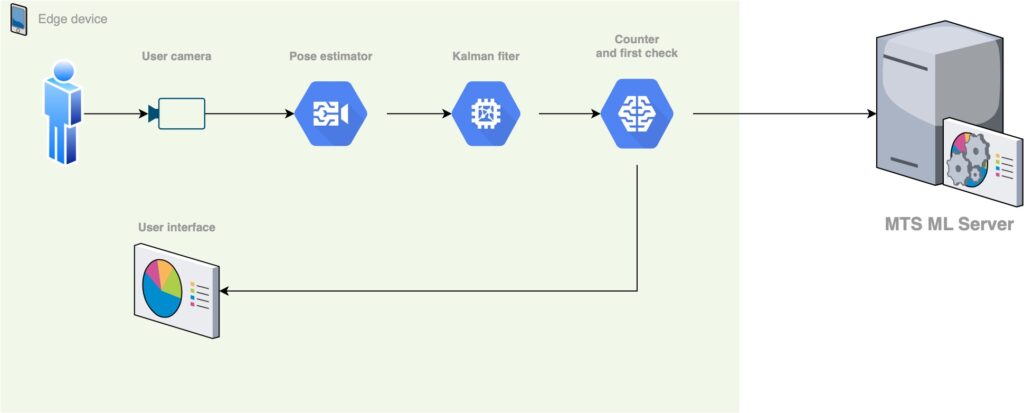
Основные компоненты ML на клиентском устройстве
- Детектор определения ключевых точек скелета человека. Детектор, который несет в себе главную часть Computer Vision. Перенос данного компонента на различные фреймворки и будет главной темой статьи. Его функция – прием кадров с человеком и вывод координат ключевых точек, найденных в каждом кадре. Это stateless компонент, который может быть запущен в режиме batch кадров.
- Фильтр Калмана для ключевых точек. Данный компонент реализует сглаживание и фильтрацию данных, полученных от pose estimator. В данном фильтре мы используем особенность постоянной частоты кадров, физической природы ключевых точек (суставы не могут перемещаться с бесконечно большой скоростью и ускорением) и связностью кадров в видеозаписи. Реализация данного компонента сыграла также большую роль в переносе, так как добавляла вычисления в обычном CPU.
- Упрощенный модуль подсчета раз и оценки правильности выполнения упражнений. Данный модуль выполеняет простые операции по оценка завершенности выполнения подхода и оценивает евристикой правильность выполнения упражнения. Данный модуль позволяет добавить обратную связь в режиме реального времени для пользователя. Телефон начинает голосом считать выполненные разы и указывать на наиболее грубые ошибки. Время выполнения данного модуля чаще всего было крайне мало по сравнению с определением позы и фильтрацией точек.
- Отправка видео и результатов на сервер. Пользователь через какое-то время получает полный отчет с подробным разбором ошибок и рекомендациями по дальнейшей тренировке.
Выбор платформы для переноса ML компонентов
Требования к платформам, текущее состояние дел
У нас было два принципиально различных способа использования продукта:
- Мобильной устройство клиента, Android или iPhone, аппараты могут быть как новые так и старые, связь может быть может не быть, распространение идет через магазины приложений
- SBC, закрепленный в фитнес клубе или офисе, с возможным чипом TPU либо GPU, стабильным ethernet, фиксированной камерой, развертывание софта происходит CI/CD методиками
В первом случае наш выбор состоял из Core ML, TFlite, ML Kit, PyTorch Mobile. Мы сразу оставили только мультиплатформенные фреймворки, для сокращения времени на исследование, отбросив Core ML и ML Kit.
Из фреймворков TFlite и PyTorch Mobile мы выбрали по принципу – максимальное переиспользование. Одна наша команда уже к тому времени работала с переносом кода на tflite, и у них были положительные отзывы по его работе. Наша мобильная разработка также оказалась знакома с его реализацией на Android. Поэтому мы решили в первом случае использовать TFlite.
Второй случай был интереснее, потому что к тому моменту сразу несколько компаний выпустило интересные продукты, связанные с Edge computing. Такие как Movidius 2 от Intel, Coral Dev Board и Coral USB TPU от Google и Jetson Nano от Nvidia + несколько китайских компаний выпустили свои чипы и платы на них для нейросетей.
Получилась такая ситуация:

Не упрощало жизнь и то, что каждый чип нуждался в своих подготовительных работах, работал на своем фреймворке, и имел разную производительность как в вычислениях для нейронных сетей так и для математики и кодирования декодирования видео.
По итогам анализа чипов и цен на них в России/доступности для массовой закупки были выбраны такие платы: Jetson nano, RPI+Movidius. Дополнительным участником стал Google Dev Board + Google Coral, они хоть и не были доступны в России, но по отзывам в сети отличались большой скоростью работы с нейросетями, плюс у них был фреймворк, очень похожий на tflite, который мы уже взяли в работу.
Финальный выбор был такой:

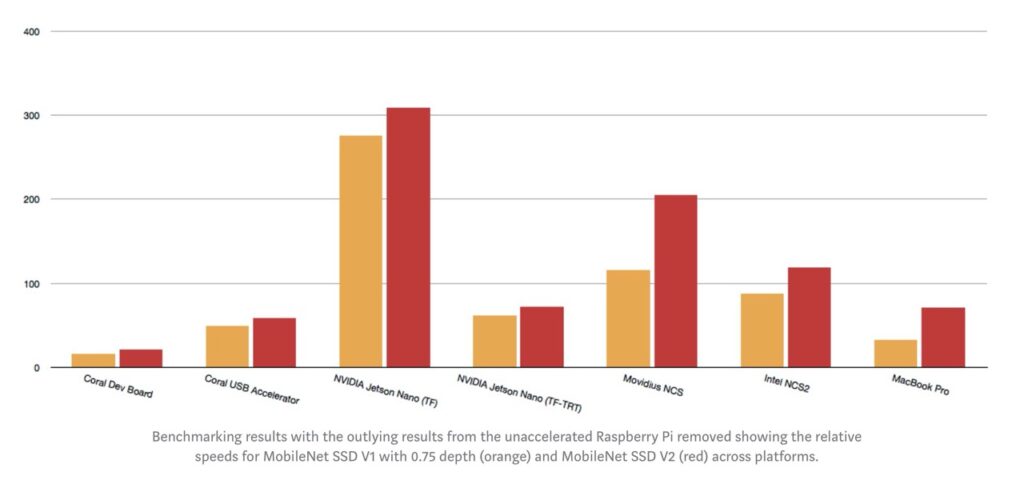
Бенчмарки устройств, найденные в сети. Что мы ожидали.
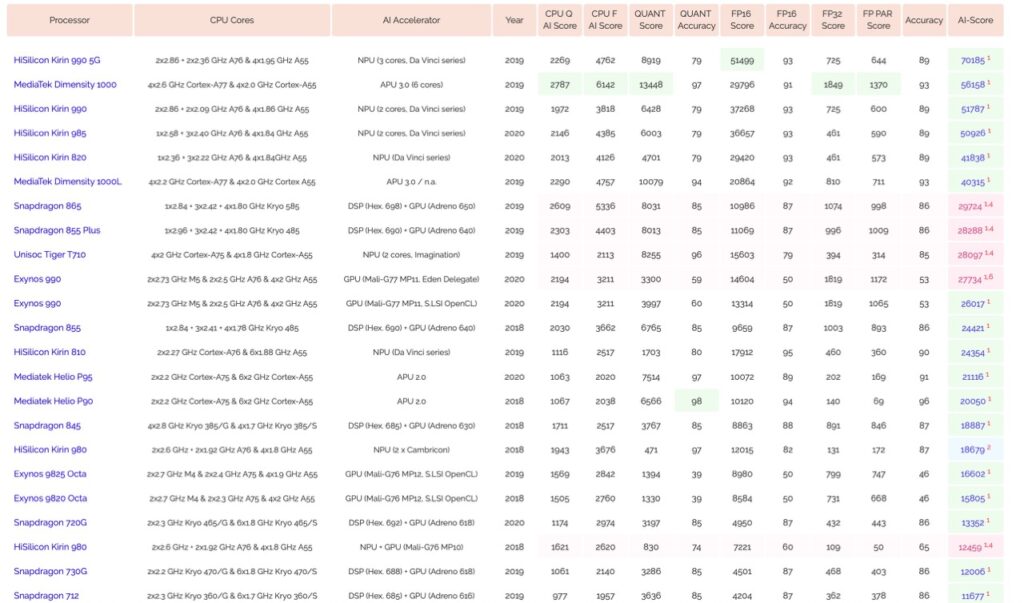
При выборе устройств мы выбирали в том числе и по бенчмаркам, представленным компаниями, производящими устройства. Эти результаты интересны тем, что по факту каждая компания представляет те цифры, которые интересны ей, что не удивительно. У каждого бенчмарка всегда оказывается приписка под звездочкой, которая объясняет, как он был получен.
Посмотрим на сводные таблицы по SBC TPU и Mobile SoC:
https://medium.com/@aallan/benchmarking-edge-computing-ce3f13942245
http://ai-benchmark.com/ranking
https://dl.acm.org/doi/fullHtml/10.1145/3368305

https://artizans.ai/posts/coreml-benchmark-on-iphone-11/
В целом, что мы вынесли из данных графиков и таблиц – это самый медленный чип, на который надо ориентироваться при оптимизации детектора. В случае с SBC это Movidius первой версии, хорошо, что он у нас уже был. В случае с мобильными телефонами – это телефоны 2018 года выпуска и новее.
Если вы хотите начать запускать нейронные сети на оконечных устройствах, не смотрите на абсолютные цифры в графиках, смотрите на относительные, они показывают реальное положение дел, с поправкой, что разные чипы имеют предпочтения в фреймворках и архитектурах сетей.
Перенос и запуск определения позы на различных устройствах
Постановка задачи
Для определения позы на сервере мы используем стандартную библиотеку openpose, обученную на датасете COCO, с размером кадра 400 по большой стороне.
Данная библиотека одной из возможных вариаций использует фреймворк caffe, который мы используем с библиотекой CUDA. С учетом всех оптимизаций, на серверном железе мы имеет около 90 фпс на одной ноде, что позволяет нам обрабатывать до 3 одновременных видео и оставляет возможность для горизонтального масштабирования.
Точность полученных после распознавания результатов проверяется в ручной разметке в формате – хороший или плохой кадр. В терминах метрик мы измеряли Object Keypoint Similarity (OKS), по границе в 0,7.
Модель на сервере на тестовых видео достигает точности в 94 процента. Выпады модели компенсируются фильтром Калмана, что позволяет достигать максимально близких к реальности данных, без резких выпадов и скачков, что требуется для дальнейшей оценки правильности подхода.
Для переноса модели мы рассматривали все возможности по минимальному переиспользованию готового кода и не ограничивались уже использованной моделью.
Наша задача была в запуске модели определения позы на скорости, позволяющей в реальном времени определить завершенность подхода и сделать первичные предсказания по правильности упражнения.
Путем экспериментов была получена граница в 10 кадров в секунду.
Ограничения по точности снизу были в 85% корректных кадров.
Работа оптимизатора для ML на слабых устройствах
Работа оптимизатора предполагает основные шаги для ускорения моделей и уменьшения их размера.
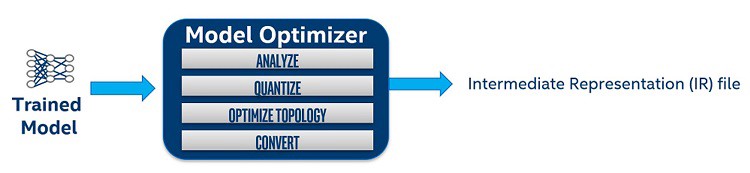
- Квантование
- Заморозка
- Объединение слоев
Рассмотрим данные шаги в общем случае:
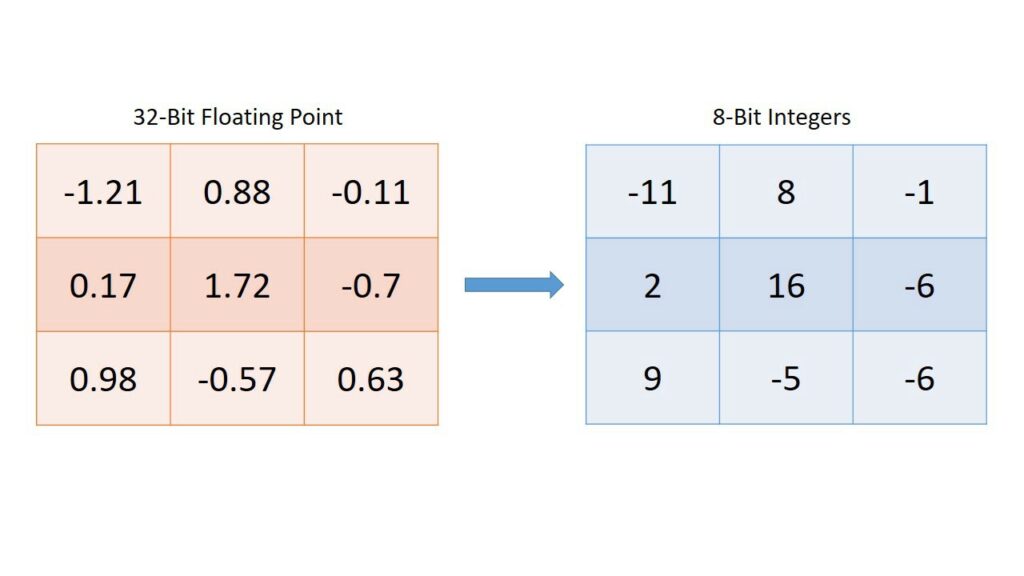
В случае квантования мы заменяем коэффициенты в нейронной сети на числа с меньшей точностью, такие как fp16 (с плавающей точкой половинной точности) или int8 (целочисленные). Зачем мы это делаем, и почему нельзя это сделать сразу?
В случае с обучением сети мы не можем использовать слишком маленькую точность, так как это автоматически увеличит минимальный шаг обучения сети либо привнесет в обучение не самое полезное квантование. Иначе говоря, сеть будет учиться плохо.
В случае работы сети в продуктиве, нам становиться критичен его размер, на который сильно влияет размер каждого коэффициента, так и ее скорость. Если с размером понятно – он линейно зависит от точности квантования, то со скоростью интереснее – она сильно зависит от того, на какой системе запускается сеть. Так, на старых видеокартах вместо выйгрыша в скорости вы можете потерять, а на старых процессорах потерять еще сильнее. В то время как на новых видеокартах прирост может составлять разы.
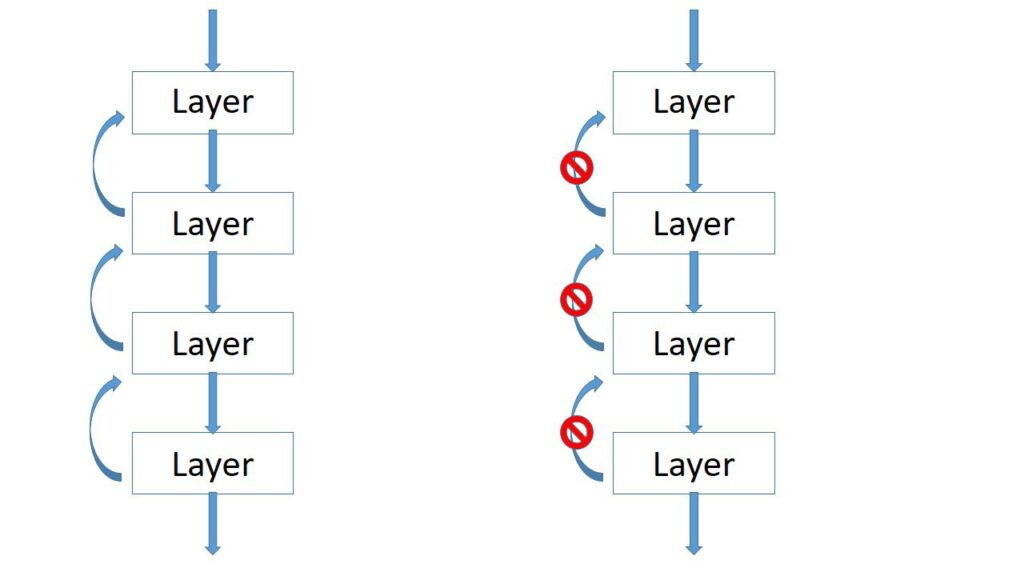
При заморозке нейронной сети происходит удаление всех операций, необходимых только для обучения и не нужных для прогона сети. А так же фиксация всех параметров сети в виде констант, что уменьшает ее размер и повышает скорость выполнения.
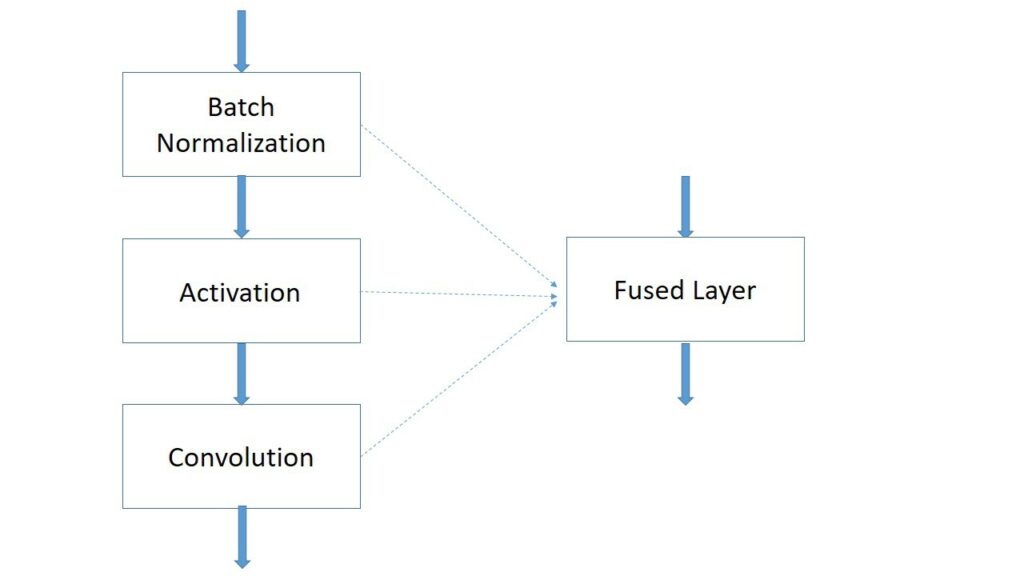
Объединение слоев – один из самых сложных и процессов оптимизации. Каждая операция в нейронной сети выполняется последовательно для каждых входных данных. Таким образом, для ускорения сети количество операций, слоев сети, необходимо уменьшать. Это просто и логично, но для обучения сети не применимо. Так как при объединении слоев мы сократим удобство в фиксации параметров каждого слоя и усложним себе задачу.
В случае работы исключительно для прохода вперед мы уже не связаны этим ограничением. В таком случае, все слои, которые могут быть объединены в один в текущем фреймворке, при объединении дают сильный прирост в скорости сети и ее размере.
Переходим к конкретным платформам.
Google Coral TPU
Данная платформа представлена корпорацией Google, включает в себя множество устройств, как для серверов так и для микрокомпьютеров.

По информации от Google, обладает хорошим соотношением производительность/энергопотребление. Особенностью является свой формат моделей, получаемый из tflite модели. Именно использование своего формата делает эту платформу менее популярной, чем стандартный tflite или jetson nano со стандартной cuda. Когда платформа только появилась, гугл непрятно отметилась тем, что для конвертации не было offline программ, и надо было отпралять в гугл каждую свою модель для конвертации. При отправке надо было согласиться с тем, что ты отдаешь в собственность гугла свою модель.
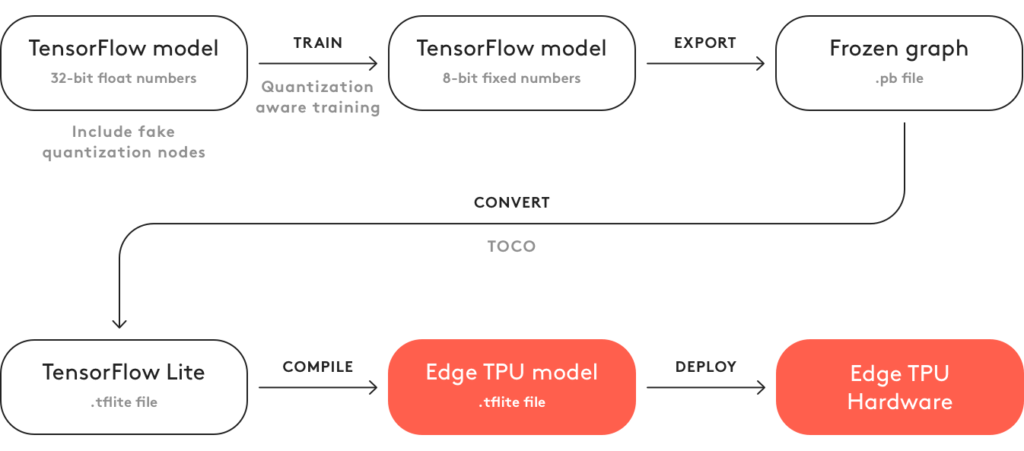
Сейчас ситуация стала лучше, появился конвертер, для запуска которого необходим unix компьютер.
Устанавливается и используется он следующим образом:
##Convert the model again with post-training quantization
# A generator that provides a representative dataset
def representative_data_gen():
dataset_list = tf.data.Dataset.list_files(flowers_dir + '/*/*')
for i in range(100):
image = next(iter(dataset_list))
image = tf.io.read_file(image)
image = tf.io.decode_jpeg(image, channels=3)
image = tf.image.resize(image, [IMAGE_SIZE, IMAGE_SIZE])
image = tf.cast(image / 255., tf.float32)
image = tf.expand_dims(image, 0)
yield [image]
converter = tf.lite.TFLiteConverter.from_keras_model(model)
# This enables quantization
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.int8]
# This ensures that if any ops can't be quantized, the converter throws an error
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
# These set the input and output tensors to uint8 (added in r2.3)
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
# And this sets the representative dataset so we can quantize the activations
converter.representative_dataset = representative_data_gen
tflite_model = converter.convert()
with open('mobilenet_v2_1.0_224_quant.tflite', 'wb') as f:
f.write(tflite_model)
##Convert to EDGETPU
! curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
! echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" | sudo tee /etc/apt/sources.list.d/coral-edgetpu.list
! sudo apt-get update
! sudo apt-get install edgetpu-compiler
! edgetpu_compiler mobilenet_v2_1.0_224_quant.tfliteВ случае, если модель содержит операции, не поддерживаемые coral-edgetpu, вычисления будут перенесены на cpu.
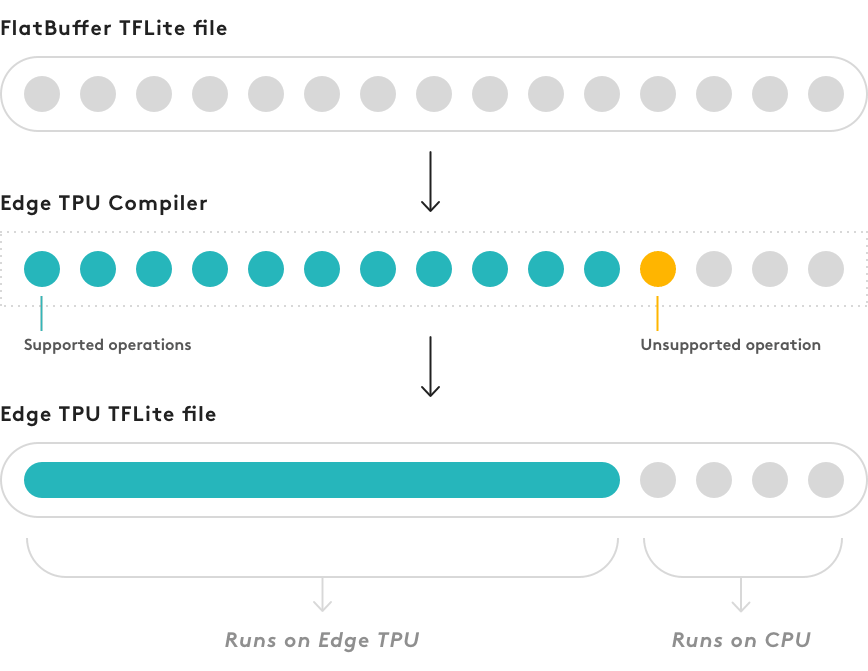
К этому надо быть готовым, если вы после конвертации видите, что модель работает медленнее, чем предполагалась.
Если модель сконвертировалась целиком, получаются очень впечатляющие результаты:
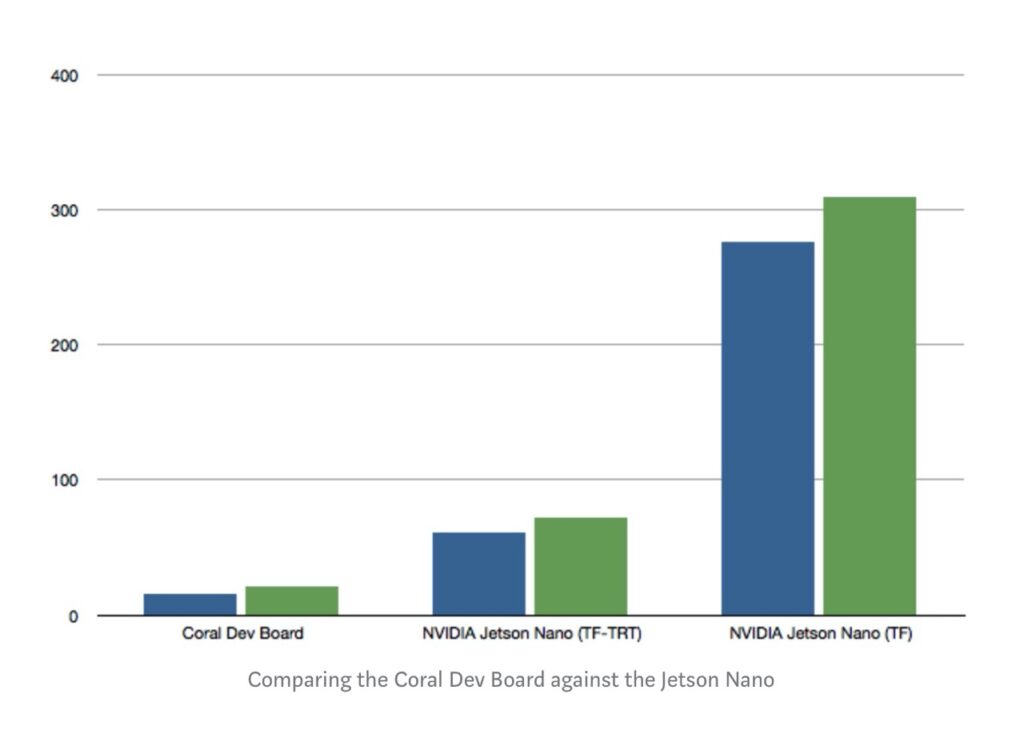
Так, на RPI с Coral USB можно получить больше 100 кадров в секунду в задаче на распознавание.
Для нашей задачи мы воспользовались готовым кодом и моделью, уже приведенной к формату coral-tpu. Код и модель были взяты с сайта coral.ai. Либо в репозитории https://github.com/google-coral/project-posenet
В дальнейшем мы конвертировали свои модели, а так же дообучали предоставленные Google. Чтобы ознакомиться с с конвертацией своей Tensorflow модели можете ознакомиться с кодом:
Данная модель использовалась с параметрами входного изображния 640 пикселей широта и 480 высота.

При данных параметрах достигалась скорость обработки в 35 кадров. Однако, дополнительная нагрузка в виде фильтра Калмана и отгрузки, получения видео уменьшил рабочее число до 15 кадров в секунду, что нас устраивало.
В таком формате точность модели показывало большое значение в 90 процентов успешных кадров.
Платформа была бы удачной для нас, но с ней были трудности ее закупки – платы coral были на тот момент запрещены на ввоз в Россию.
Intel Movidius TPU
Чип Movidius от Intel является специализированным чипов для запусков нейронных сетей для компьютерного зрения. Первый чип Movidius от intel вышел в 2016 года. До этого компания создавала чипы для компьютерного зрения и их можно встретить у Google, DJI, и китайских компаний, производителей “умных” камер.
Чип поддерживает модели в различных форматах, но предпочтительный фреймворк для него OpenVINO – собственная разработка Intel.
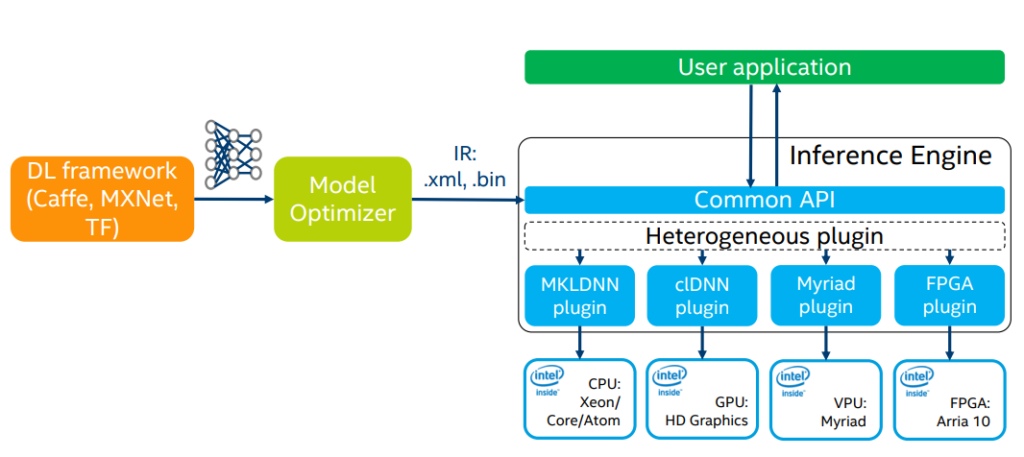
Для запуска модели в данном фреймворке ее необходимо сконвертировать.
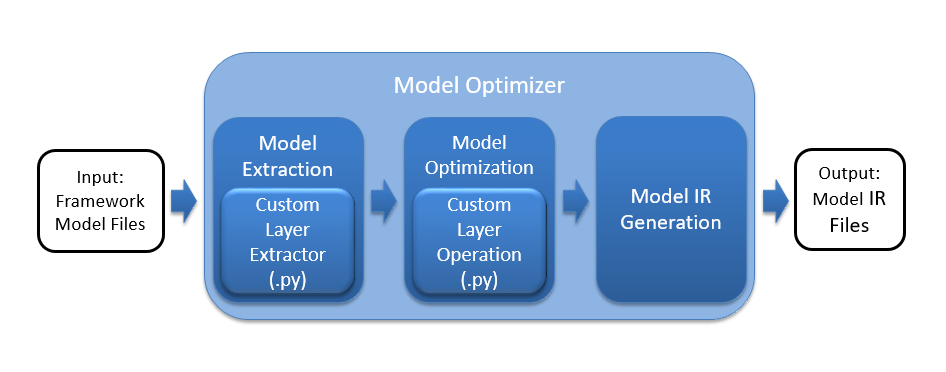
Для конвертации вам необходимо установить фреймворк OpenVino на компьютер и указать модель для конвертации с параметрами.
##Freezing Custom Models in Python
import tensorflow as tf
from tensorflow.python.framework import graph_io
frozen = tf.graph_util.convert_variables_to_constants(sess, sess.graph_def, ["name_of_the_output_node"])
graph_io.write_graph(frozen, './', 'inference_graph.pb', as_text=False)
##To convert a TensorFlow model
python3 /opt/intel/openvino/deployment_tools/model_optimizer/mo.py \
--input_model ~/Downloads/posenet_tensorflow_models/model-mobilenet_v1_075.pb \
--framework tf \
-o ~/posenet/ \
--input image \
--input_shape [1,224,224,3] \
--output "offset_2,displacement_fwd_2,displacement_bwd_2,heatmap" \
--data_type FP16Если использовать OpenPose модель, то даже на маленьком изображении можно достичь только 2 кадров в секунду, что для нас не удовлетворяющая скорость.
Для ускорения определения позы мы можем использовать другую модель: PoseNet. Она дает меньшую точность, но имеет гораздо меньшую сложность для рассчетов.
Мы использовали вариант PoseNet сети, реализованный в фреймворке tfjs, он показывал отличную скорость и приемлимую точность.
Для конвертации нам потребовалось выполнить следующие шаги:
- Выкачать tfjs модель
- Преобразовать модель к стандартному графу Tensorflow
- Преобразовать модель к OpenVino формату
В итоге мы получили три модели:
- model-mobilenet_v1_050.pb
- model-mobilenet_v1_075.pb
- model-mobilenet_v1_100.pb
Их показатели скорости получились следущие:

Точность можно оценить по гифке:

Мы остановились на варинате model-mobilenet_v1_075.pb, после всех дополнительных манипуляций, мы достигли скорости работы в 10 кадров, что было для нас допустимым.
Одним из показателей работы полученной модели, не полностью нас удовлетворяющих, была ее точность. На всем датасете она составляла порядка 80% успешных кадров. Однако мы отметили, что на хороших видео ее точность была заметно выше, до 90%.
Так как SBC устанавливается в контролируемом окружении, мы приняли эту модель с отметкой, что надо установить источник света около стенда и использовать контрастный фон.
По итогам всех работ, именно вторая версия Movidius NCS, которая обладает примерно удвоенной мощностью, в связке с RPI3. Использовалась нами в фитнес-клубах и офисах.
Характеристики, по которым она была выбрана – низкая стоимость, возможность купить у официальных поставщиков, хорошая скорость, универсальность.
Nvidia Jetson nano
Модули Nvidia Jetson представляют из себя семейство микрокопьютеров и чипов для запуска нейросетей от компании Nvidia.

На данный момент самым дешевым и слабым является jetson nano. Его стоимость в собранном виде ~ 10т рублей, что соотносится с другими SBC TPU в нашей подборки. Для нас было важно, чтобы его скорости и возможности запускать сети без конвертации хватило для нашей задачи.
Особенностью работы с платформой jetson от Nvidia, в том числе и самым маленьким из них – nano является полная поддержка CUDA, если вы работали с нейросетями, почти наверняка слышали и работали с ней.
Это подталкивает к тому, чтобы просто запустить код в таком виде, как он у вас есть, на “большом” фреймворке Tensorflow или PyTorch, что вы и можете сделать. Я первым делом ровно так и сделал, и получил цифры, в несколько раз хуже тех, что представила Nvidia. В этот момент открывается большой мир под названием TensorRT.
На картинке TensorRT описывается следующим образом:
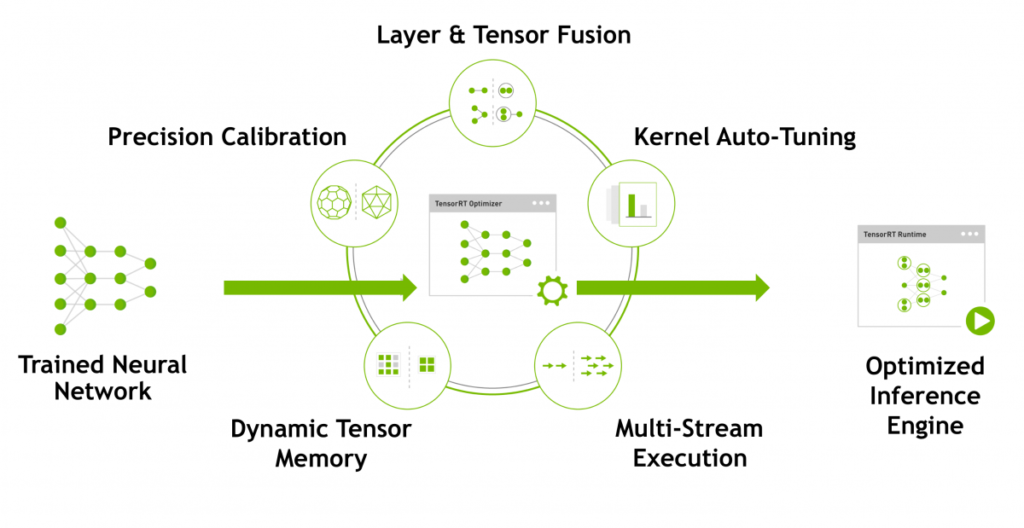
Для того, чтобы преобразовать модель в формат TensorRT, вам понадобиться устройство с его поддержкой, такое как GPU 20 серии и выше, серверные GPU поколения Tesla и новее, либо микрокомпьютеры Nvidia Jetson.
Обратите внимание, что конвертировать лучше всего на том устройстве, где будет выполнятся работа сети, так как модель будет специальным образом оптимизирована именно для данного устройства.
Если вы работаете с фреймворком Tensorflow, вы можете воспользоваться утилитой tf-trt, которая может прогонять модели в формате tf с автоматической конвертацией TensorRT.
Более того, если модель не получится полностью сковертировать, из-за ограничений версии TensotRT или устройства, часть модели выполнится на CPU.
Мы использовали для конвертации модель из tfjs, преобразованную в tensorflow
Покажем на нашем примере, как мы использовали оба подхода в нашем случае:
##Create TF graph for inference
graph = tf.Graph()
with graph.as_default():
with tf.variable_scope('net'):
net_inp = tf.placeholder(tf.float32, INPUT_SIZE, name='input')
net_out = model.model(net_inp, is_training=False)
saver = tf.train.Saver()
##Create TF session and load snapshot
sess_config = tf.ConfigProto()
sess_config.gpu_options.allow_growth = True
sess = tf.Session(graph=graph, config=sess_config)
snapshot_fpath = tf.train.latest_checkpoint(MODEL_PATH)
saver.restore(sess, snapshot_fpath)
##Freeze graph
graphdef_inf = tf.graph_util.remove_training_nodes(graph.as_graph_def())
graphdef_frozen = tf.graph_util.convert_variables_to_constants(
sess, graphdef_inf, OUTPUT_NAMES)
os.makedirs(os.path.dirname(FROZEN_GDEF_PATH), exist_ok=True)
graph_io.write_graph(graphdef_frozen, './', FROZEN_GDEF_PATH, as_text=False)
##Convert TF frozen graph to UFF graph
uff_model = uff.from_tensorflow_frozen_model(FROZEN_GDEF_PATH, [OUTPUT_NODE])
##Create TRT model builder
trt_logger = trt.Logger(trt.Logger.INFO)
builder = trt.Builder(trt_logger)
builder.max_batch_size = MAX_BATCH_SIZE
builder.max_workspace_size = MAX_WORKSPACE
builder.fp16_mode = (DATA_TYPE == trt.float16)
##Create UFF parser
parser = trt.UffParser()
parser.register_input(INPUT_NODE, INPUT_SIZE)
parser.register_output(OUTPUT_NODE)
##Parse UFF graph and build optimized inference engine
network = builder.create_network()
parser.parse_buffer(uff_model, network)
engine = builder.build_cuda_engine(network)
##Save inference engine¶
with open(ENGINE_PATH, "wb") as f:
f.write(engine.serialize())Мобильные устройства на Android и TFLite
Нашей большой задачей был переход на вычисления на мобильных телефонах. Здесь, в отличии от SBC, появлялась дополнительная сложность в виде другого языка программирования, в случае с Apple – Swift, в случае с Android – Kotlin.
Платформы отличаются не только языком, на котором необходимо реализовывать программы, но и фреймворками по умолчанию для ML и компьютерного зрения. Так, Google продвигает ML Kit и Tensorflow Lite а Apple – Core ML. У каждого подхода есть свои преимущества, подробнее надо было бы писать по серии статьей по каждому фреймворку.
Нам был необходим максимально одинаковый подход, для уменьшения затрат на разработку. Мультиплатформенных фреймворков есть несколько – самые популярные из них это PyTorch Mobile и Tensorflow Lite. Так как мы уже работали с TFLite, мы выбрали данный способ.
Общая схема работы TFLite представлена ниже:
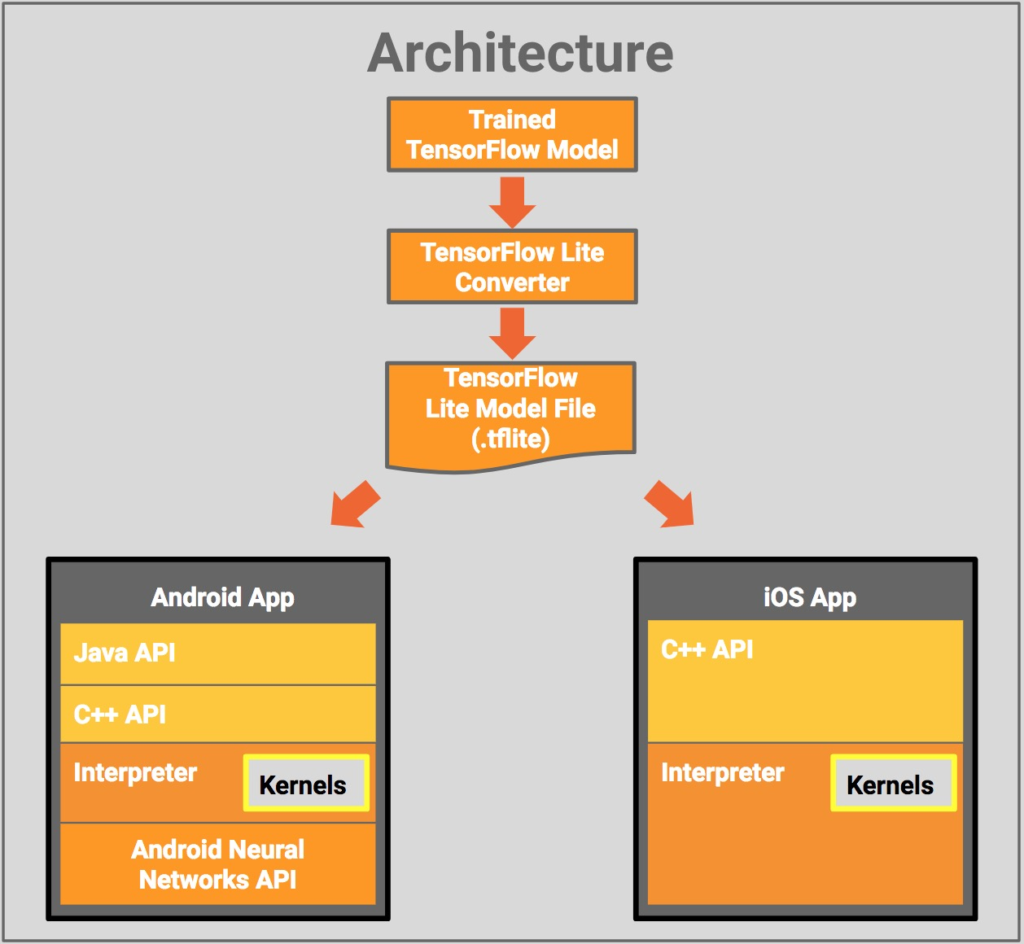
Для iOS и Android уже есть реализованные программы, использующие модели как классификации так и детекции. Программный код вы можете взять оттуда:
- https://www.tensorflow.org/lite/guide/ios
- https://www.tensorflow.org/lite/guide/android
- https://heartbeat.fritz.ai/machine-learning-on-android-computer-vision-c38c4072acd8
Модель для работы сети мы использовали ту, которую получили для работы с Coral TPU.
На мобильных устройствах мы получили следующие результаты:
Итоги переноса
Мы запустили сервис в фитнес-центрах и офисах на платформе raspberry pi + movidius. К времени запуска вышел RPI4, мы перенесли код на него, получилось немного быстрее, за счет более быстрого CPU, но мы получили проблемы с перегревом, которые решились покупкой корпусов с большим радиатором.
До сих пор сложность вызывают случаи поведения людей, не предусмотренные моделью, сложности с питанием и закрытие фитнес клубов и бизнес центов.
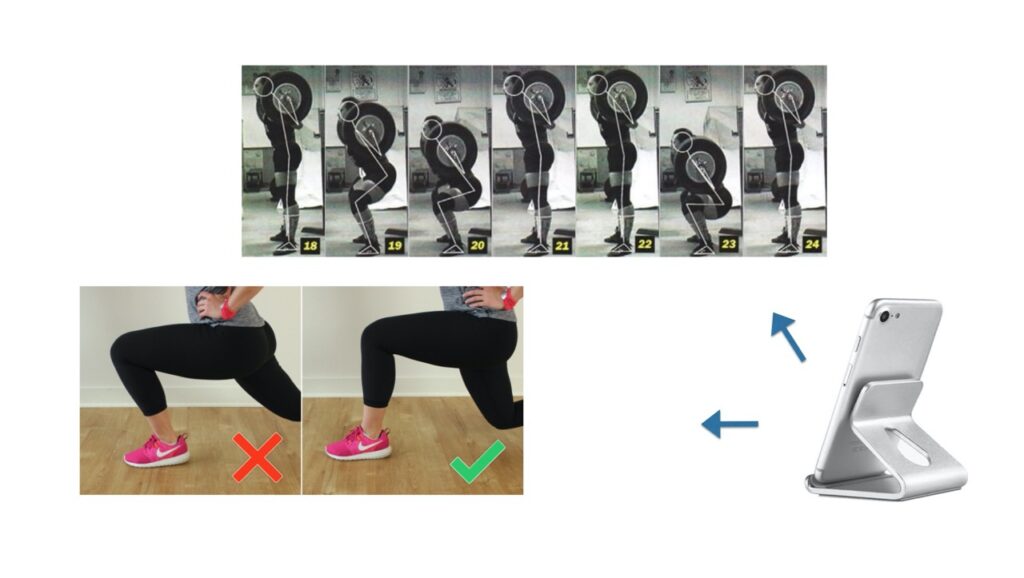
Примеры как мы работаем на спортивном уголке в офисе Worki:
Дальнейшие шаги
По работе мы столкнулись с большим количеством интересных задач,
не описанных тут, такой как первичная настройка каждой платы (тут бооольшой простор фантазии у программистов открывается). Удаленное управление устройствами. Бесконечный мир мобильных телефонов, где совсем своя жизнь. Трудности закупки большого числа устройств и так далее.
Открыли для себя область запуска моделей на оконечных устройствах. Оказались полностью довольны, область открыла нам множество перспектив.
В данный момент в МТС идут большие проекты, где используются сотни edge устройств. Приходите к нам!



0 Comments